딥러닝 용어 정리, L1 Regularization, L2 Regularization 의 이해, 용도와 차이 설명
제가 공부하고 정리한 것을 나중에 다시 보기 위해 적는 글입니다. 제가 잘못 설명한 내용이 있다면 알려주시길 부탁드립니다. 사용된 이미지들의 출처는 본문에 링크로 나와 있거나 글의 가장 마지막에 쓰여 있습니다.
감사합니다.
L1 Regularization 과 L2 Regularization 을 설명하기 위한 글입니다.
결론부터 얘기하자면 L1 Regularization 과 L2 Regularization 모두 Overfitting(과적합) 을 막기 위해 사용됩니다.
위 두 개념을 이해하기 위해 필요한 개념들부터 먼저 설명합니다. 이 글의 순서는 아래와 같습니다.
1. Norm
2. L1 Norm
3. L2 Norm
4. L1 Norm 과 L2 Norm 의 차이
5. L1 Loss
6. L2 Loss
7. L1 Loss, L2 Loss 의 차이
8. Regularization
9. L1 Regularization
10. L2 Regularization
11. L1 Regularization, L2 Regularization 의 차이와 선택 기준
1. Norm
Norm 은 벡터의 크기(혹은 길이)를 측정하는 방법(혹은 함수)입니다. 두 벡터 사이의 거리를 측정하는 방법이기도 합니다. 한국어로 적을 땐 '노름' 이라고 발음기호대로 적는데, 막상 제 귀엔 영미권에서의 발음은 '노ㄹㅡ엄' 으로 들립니다.

*여기서 p 는 Norm 의 차수를 의미합니다. p = 1 이면 L1 Norm 이고, P = 2 이면 L2 Norm 입니다.
*n은 해당 벡터의 원소 수 입니다.
이 글에선 L1 Norm 과 L2 Norm 만 다루고자 합니다. 이외의 Norm 의 더 자세한 정의나 다양한 종류에 대해선 아래 위키피디아 링크를 참고해주세요.
https://en.wikipedia.org/wiki/Norm_(mathematics)
2. L1 Norm

where

are vectors

위키피디아(링크)의 Taxicab geometry 의 정의를 그대로 가져왔습니다. 쉽게 얘기해서 L1 Norm 은 벡터 p, q 의 각 원소들의 차이의 절대값의 합입니다.
예를 들어 벡터 p =(3, 1, -3), q = (5, 0, 7) 이라면 p, q의 L1 Norm 은
|3-5| + |1-0| + |-3 -7| = 2 + 1 + 10 = 13 이 됩니다.
3. L2 Norm

위키피디아(링크) 의 Norm 의 예시 중 Euclidean Norm 의 수식을 가져왔습니다. L2 Norm 은 벡터 p, q 의 유클리디안 거리(직선 거리) 입니다. 여기서 q 가 원점이라면 벡터 p, q의 L2 Norm 은 벡터 p 의 원점으로부터의 직선거리라고 할 수 있습니다.
위 수식이 바로 p = (x_1, x_2, ... , x_n), q = (0, 0, ... , 0) 라고 할 수 있습니다.
4. L1 Norm 과 L2 Norm 의 차이
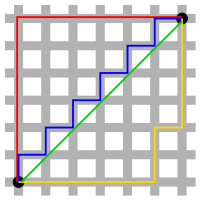
검정색 두 점사이의 L1 Norm 은 빨간색, 파란색, 노란색 선으로 표현 될 수 있고, L2 Norm 은 오직 초록색 선으로만 표현될 수 있습니다. L1 Norm 은 여러가지 path 를 가지지만 L2 Norm 은 Unique shortest path 를 가집니다.
예를 들어 p = (1, 0), q = (0, 0) 일 때 L1 Norm = 1, L2 Norm = 1 로 값은 같지만 여전히 Unique shortest path 라고 할 수 있습니다.
5. L1 Loss

y_i 는 실제 값을, f(x_i)는 예측치를 의미합니다. 실제 값과 예측치 사이의 차이(오차) 값의 절대값을 구하고 그 오차들의 합을 L1 Loss 라고 합니다. 이를 Least absolute deviations(LAD), Least absolute Errors(LAE), Least absolute value(LAV), Least absolute residual(LAR), Sum of absolute deviations 라고 부릅니다.
6. L2 Loss

L2 Loss 는 오차의 제곱의 합으로 정의됩니다. 이를 Least squares error(LSE) 라고 부릅니다.
7. L1 Loss, L2 Loss 의 차이
L2 Loss 는 직관적으로 오차의 제곱을 더하기 때문에 Outlier 에 더 큰 영향을 받습니다. "L1 Loss 가 L2 Loss 에 비해 Outlier 에 대하여 더 Robust(덜 민감 혹은 둔감) 하다." 라고 표현 할 수 있습니다.
Outlier 가 적당히 무시되길 원한다면 L1 Loss 를 사용하고, Outlier 의 등장에 신경써야 하는 경우라면 L2 Loss 를 사용하는 것이 좋겠습니다.
L1 Loss 는 0인 지점에서 미분이 불가능하다는 단점 또한 가지고 있습니다.
8. Regularization
보통 번역은 '정규화' 라고 하지만 '일반화' 라고 하는 것이 이해에는 더 도움이 될 수도 있습니다. 모델 복잡도에 대한 패널티로 정규화는 Overfitting 을 예방하고 Generalization(일반화) 성능을 높이는데 도움을 줍니다. Overfitting 을 예방하는 방법으로는 L1 Regularization, L2 Regularization, Dropout, Early stopping 등이 있습니다.

출처[1]
model 을 쉽게 만드는 방법은 단순하게 cost function 값이 작아지는 방향으로만 진행하는 것입니다. 이럴 경우 특정 가중치가 너무 큰 값을 가지기 때문에 model 의 일반화 성능이 떨어지게 될 것입니다. 위 그래프에서 actual function 이 target function 이라고 했을 때, model 이 overfitting 된 것을 알 수 있습니다.

Regularization 은 이렇게 특정 가중치가 너무 과도하게 커지지 않도록 하여 모델을 위 그래프처럼 만들어줍니다.
9. L1 Regularization

L1 Regularization 은 위 수식처럼 표현할 수 있습니다. 논문에 따라서 앞에 분수로 붙는 1/n 이나 1/2 가 달라지는 경우가 있는데 L1 Regularization 의 개념에서 가장 중요한 것은 cost function 에 가중치의 절대값을 더해준다는 것이기 때문에 1/n 이나 1/2 가 달라지는 경우는 연구의 case 에 따라 다르다고 이해하고 넘어가겠습니다(이는 L2 Regularization 또한 같습니다).
기존의 cost function 에 가중치의 크기가 포함되면서 가중치가 너무 크지 않은 방향으로 학습 되도록 합니다. 이때 λ 는 learning rate(학습률) 같은 상수로 0에 가까울 수록 정규화의 효과는 없어집니다.
L1 Regularization 을 사용하는 Regression model 을 Least Absolute Shrinkage and Selection Operater(Lasso) Regression 이라고 부릅니다.
10. L2 Regularization

기존의 cost function 에 가중치의 제곱을 포함하여 더함으로써 L1 Regularization 과 마찬가지로 가중치가 너무 크지 않은 방향으로 학습되게 됩니다. 이를 Weight decay 라고도 합니다.
L2 Regularization 을 사용하는 Regression model 을 Ridge Regression 이라고 부릅니다.
11. L1 Regularization, L2 Regularization 의 차이와 선택 기준
먼저 Regularization 의 의미를 다시 한번 생각해보면, 가중치 w 가 작아지도록 학습한 다는 것은 결국 Local noise 에 영향을 덜 받도록 하겠다는 것이며 이는 Outlier 의 영향을 더 적게 받도록 하겠다는 것입니다.

위와 같은 벡터 a 와 b에 대해서 L1 Norm 과 L2 Norm 을 계산하면 각각 아래와 같습니다.


L2 Norm 은 각각의 벡터에 대해 항상 Unique 한 값을 내지만, L1 Norm 은 경우에 따라 특정 Feature(벡터의 요소) 없이도 같은 값을 낼 수 있다는 뜻입니다.
L1 Norm 은 파란색 선 대신 빨간색 선을 사용하여 특정 Feature 를 0으로 처리하는 것이 가능하다고 이해할 수 있습니다. 다시 말하자면 L1 Norm 은 Feature selection 이 가능하고 이런 특징이 L1 Regularization 에 동일하게 적용 될 수 있는 것입니다. 이러한 특징 때문에 L1 은 Sparse model(coding) 에 적합합니다. L1 Norm 의 이러한 특징 때문에 convex optimization 에 유용하게 쓰인다고 합니다.

출처[2]
단, L1 Regularization 의 경우 위 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요합니다.
↓이 글이 도움이 되셨다면 공감을 표시하는 아래 하트를 눌러주세요. 구독을 눌러주시면 더 좋구요! 감사합니다.
참고한 자료들
[1] https://towardsdatascience.com/regularization-the-path-to-bias-variance-trade-off-b7a7088b4577
[2] https://www.quora.com/When-would-you-chose-L1-norm-over-L2-norm
[3] https://www.stand-firm-peter.me/2018/09/24/l1l2/
[4] https://m.blog.naver.com/laonple/220527647084
[5] https://ratsgo.github.io/machine%20learning/2017/10/12/terms/
